
当我们在讨论 Go 语言的优势时,总是会提到它出色的垃圾回收能力。但是,什么是垃圾回收?Go 的垃圾回收器又是如何工作的呢?为什么它能在保证程序性能的同时,还能自动管理内存?
今天,我们就来深入剖析 Go 语言的垃圾回收机制,从最基础的概念开始,逐步深入到三色标记法、写屏障等高级概念,让你彻底理解 Go 是如何在幕后默默守护你的程序的。
为啥需要垃圾回收?
想象一下你正在经营一家繁忙的咖啡厅。每天有无数的顾客进进出出,使用着咖啡厅里的桌椅、杯具。如果没有清洁工定期收拾桌子、回收杯具,很快咖啡厅就会被垃圾淹没,新顾客根本找不到可用的座位。
程序的内存管理也是如此。在程序运行过程中,我们不断地创建对象、分配内存,这些对象就像咖啡厅里的杯具一样。当这些对象不再被使用时,它们就变成了"垃圾",占用着宝贵的内存空间。如果不及时清理,程序最终会因为内存耗尽而崩溃。
在 C 语言中,程序员需要手动管理内存:
char *buffer = malloc(1024); // 申请内存
// 使用 buffer...
free(buffer); // 手动释放内存这种手动管理方式虽然给了程序员完全的控制权,但也带来了很多问题:
内存泄漏:忘记释放不再使用的内存,导致内存占用越来越高。就像咖啡厅的服务员忘记收拾桌子,最终没有空桌可用。
悬空指针:释放内存后仍然使用指向该内存的指针,导致程序崩溃。这就像服务员把还在使用的桌子收走了,顾客瞬间懵圈 😵💫。
重复释放:同一块内存被释放多次,导致程序行为未定义。

这些问题在大型项目中尤其突出,程序员需要花费大量精力在内存管理上,而不是专注于业务逻辑的实现。
垃圾回收就是为了解决这些问题而诞生的。它就像一个智能的清洁工,能够自动识别哪些内存不再被使用,并将其回收,释放给程序重新使用。这样,程序员就可以专注于编写业务逻辑,而不用担心内存管理的细节。
Go 语言的垃圾回收器更是将这个理念发挥到了极致:它不仅能自动回收垃圾,还能在保证程序低延迟的同时高效地工作。这对于要使用 Web 服务、云计算等高并发场景的 Go 程序来说,简直是福音。
回收谁?
既然要做垃圾回收,首先得搞清楚:什么样的对象算是"垃圾"?
在程序的世界里,判断一个对象是否为垃圾的标准很简单:如果这个对象不能再被程序访问到,那它就是垃圾。更专业地说,如果从程序的根对象(比如全局变量、栈上的变量)出发,通过任何引用链都无法到达这个对象,那这个对象就可以被回收了。
让我们用一个具体的例子来理解:
func createObjects() (*Person, *Person, *Person) {
a := &Person{Name: "Alice"} // a 指向一个 Person 对象
b := &Person{Name: "Bob"} // b 指向另一个 Person 对象
a.Friend = b // Alice 的朋友是 Bob
b.Friend = a // Bob 的朋友是 Alice
c := &Person{Name: "Charlie"} // c 指向第三个对象
// 函数结束时,局部变量 a、b、c 都会被销毁
// 但它们指向的对象在堆上,需要垃圾回收器处理
return a, b, c // 👈 逃逸!因为返回给函数外部
}当 createObjects 函数执行完毕后,局部变量 a、b、c 都被销毁了。这时候:
- Alice 和 Bob 对象虽然互相引用,但从程序的根对象出发已经无法到达它们,所以它们都是垃圾。
- Charlie 对象同样无法从根对象到达,也是垃圾。
这里有个有趣的情况:Alice 和 Bob 互相引用,形成了一个环形引用。如果使用简单的引用计数法(每个对象记录有多少个引用指向它),这两个对象的引用计数都不为零,无法被回收,从而造成内存泄漏。

Go 的垃圾回收器采用的是可达性分析方法,它从根对象出发,沿着引用链进行遍历,所有能够遍历到的对象都被标记为"活跃",其余的对象则被认为是垃圾。这种方法能够正确处理环形引用的情况。
根对象通常包括:
- 全局变量
- 栈上的局部变量
- 寄存器中的变量
- 静态变量等
这些根对象就像是一张巨大网络的起点,垃圾回收器沿着这些起点编织的"引用网"来确定哪些对象还"活着",哪些已经成为了无人问津的"孤儿"。
古早时期的垃圾回收:标记-清除
在垃圾回收的发展史上,标记-清除(Mark-and-Sweep)算法可以说是最经典、最直观的垃圾回收算法。虽然现在的 Go 已经使用了更加先进的算法,但理解标记-清除算法有助于我们更好地理解后续的改进。
标记-清除算法的工作过程非常简单,就像它的名字一样,分为两个阶段:
标记阶段(Mark Phase):从根对象出发,沿着引用链遍历所有可达的对象,并给这些对象打上"活跃"的标记。这个过程就像在一个巨大的迷宫中,从入口开始,沿着所有可能的路径行走,给经过的每个房间都贴上一个绿色的标签。
清除阶段(Sweep Phase):遍历整个堆内存,将所有没有标记的对象回收掉,释放它们占用的内存空间。这就像在迷宫中的大扫除,把所有没有绿色标签的房间都清空。
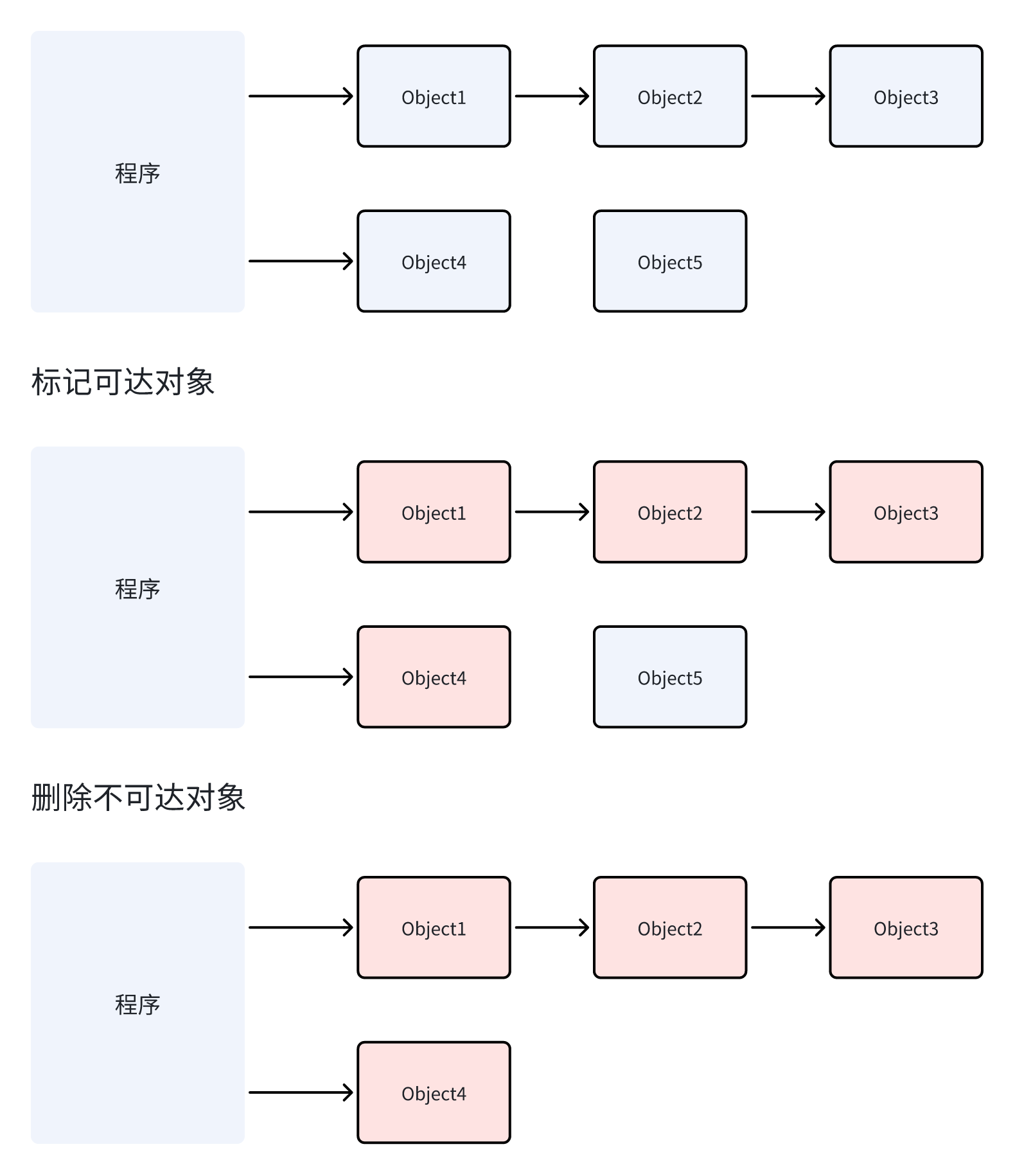
让我们用代码来模拟这个过程:
// 伪代码:标记阶段
func mark() {
workList := getRootObjects() // 获取所有根对象
for len(workList) > 0 {
obj := workList.pop()
if !obj.isMarked() {
obj.setMark(true) // 标记对象
// 将该对象引用的所有对象加入工作列表
for ref := range obj.getReferences() {
workList.push(ref)
}
}
}
}
// 伪代码:清除阶段
func sweep() {
for obj := range getAllObjects() {
if obj.isMarked() {
obj.setMark(false) // 清除标记,为下次 GC 做准备
} else {
freeObject(obj) // 回收未标记的对象
}
}
}标记-清除算法的优点很明显:
- 算法简单:逻辑清晰,容易理解和实现
- 处理环形引用:能够正确处理对象间的环形引用
- 空间效率高:只需要一个比特位来存储标记信息
但是,它也有一个致命的缺点:需要 STW(Stop The World)。
STW 意味着在垃圾回收期间,程序的所有线程都必须停止运行,等待垃圾回收完成。这就像是整个咖啡厅在清洁时间必须停止营业,所有顾客都要等在门外。
Go 使用一个叫 GOGC 的参数(默认值为 100)控制 GC 触发频率,在一次 GC 结束后,如果堆的大小增长了 GOGC%,就会触发下一次 GC:
举例:GC 后堆大小是 100MB → 增长到 200MB 会触发下一次 GC;如果 GOGC=100,意思是“堆大小增长一倍后触发”;同时,每次内存分配时都会检查是否超过阈值;没有定时器、后台 GC 线程,纯被动触发,所有 goroutine 暂停(STW)。

对于早期的程序来说,这可能不是什么大问题。但对于现代的服务器应用,特别是那些需要低延迟响应的系统,STW 时间过长是绝对不能容忍的。想象一下,如果一个处理用户请求的服务器因为垃圾回收而暂停几百毫秒,用户体验将会多么糟糕。
Go 早期的垃圾回收器确实使用过标记-清除算法,但随着对性能要求的不断提高,Go 团队开始寻求更好的解决方案。这就引出了我们接下来要讨论的三色标记算法。
并发回收,引入三色标记和插入删除屏障
为了解决标记-清除算法 STW 时间过长的问题,Go 的垃圾回收器进化出了一个更加精妙的算法:三色标记法。
三色标记法的核心思想是将对象分为三种颜色:
白色(White):未被访问的对象,垃圾回收结束时,所有白色对象都会被回收。
灰色(Gray):已被访问但其引用的对象还未全部访问的对象,这些对象处于"待处理"状态。
黑色(Black):已被访问且其引用的所有对象都已被访问的对象,这些对象确定是活跃的。
这个过程就像是在一个巨大的图书馆中进行图书整理:
- 刚开始时,所有的书都是白色的(未处理)
- 管理员从入口开始,将看到的书标记为灰色(发现但未完全处理)
- 对于每本灰色的书,管理员会检查它引用的所有其他书籍,并将这些书也标记为灰色
- 当一本书的所有引用都被检查完毕后,这本书就变成黑色(完全处理)
- 最终,所有白色的书籍都被认为是无用的,可以被清理掉
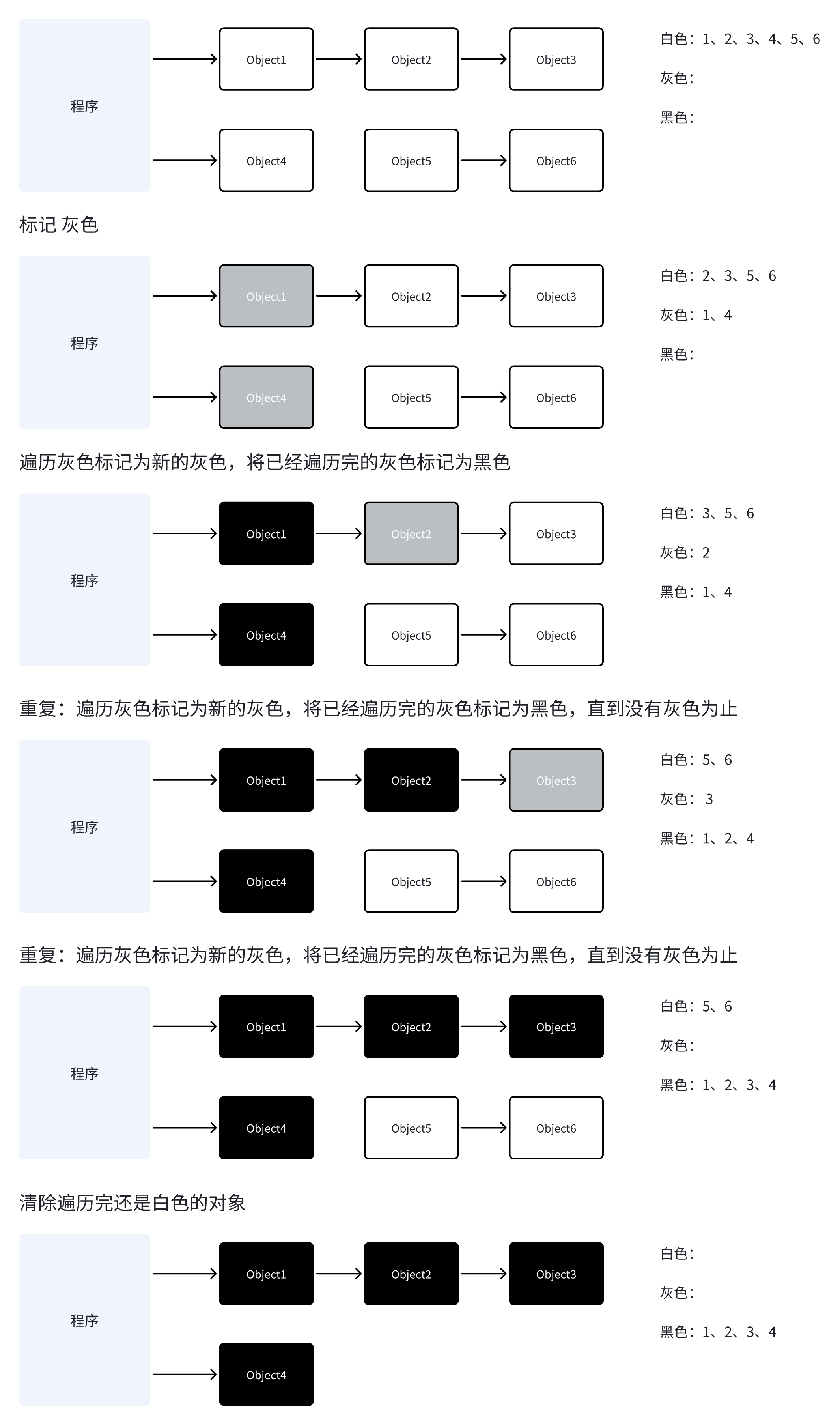
三色标记法的工作流程如下:
- 初始化:所有对象都标记为白色,将根对象标记为灰色
- 标记过程:
- 从灰色对象集合中取出一个对象
- 将该对象标记为黑色
- 将该对象直接引用的所有白色对象标记为灰色
- 重复上述过程,直到没有灰色对象
- 清除过程:回收所有白色对象
// 伪代码:三色标记算法
func triColorMark() {
// 初始化:所有对象都是白色
grayObjects := make([]Object, 0)
// 将根对象标记为灰色
for root := range getRootObjects() {
root.setColor(GRAY)
grayObjects = append(grayObjects, root)
}
// 处理所有灰色对象
for len(grayObjects) > 0 {
obj := grayObjects[0]
grayObjects = grayObjects[1:]
// 将当前对象标记为黑色
obj.setColor(BLACK)
// 将其引用的白色对象标记为灰色
for ref := range obj.getReferences() {
if ref.getColor() == WHITE {
ref.setColor(GRAY)
grayObjects = append(grayObjects, ref)
}
}
}
// 清除所有白色对象
for obj := range getAllObjects() {
if obj.getColor() == WHITE {
freeObject(obj)
}
}
}三色标记法下还需要 STW 吗?
理论上来说,三色标记法确实为并发垃圾回收提供了可能。既然我们可以用三种颜色来表示对象的状态,那么是否可以让垃圾回收器和用户程序同时运行呢?
答案是:可以,但有条件。
如果在垃圾回收过程中,用户程序不修改任何对象之间的引用关系,那么三色标记法可以完美地并发工作。但现实中,用户程序总是在不断地创建新对象、修改引用关系,这就可能导致一些严重的问题。
如果不用 STW 呢?
让我们看看如果不使用 STW,在并发标记过程中可能出现什么问题。
问题一:对象丢失
考虑这样一个场景,在某次我们执行垃圾回收时,别的 goroutine 正在并发地修改对象引用关系:
- 对象 A(黑色)引用对象 B(灰色)
- 对象 B 引用对象 C(白色)
- 用户程序让对象 A 直接引用对象 C:
A.ref = C - 同时,用户程序删除了 B 对 C 的引用:
B.ref = nil
此时就出现了问题:
- 对象 A 已经是黑色,垃圾回收器不会再检查它的引用
- 对象 B 会被标记为黑色,但它已经不再引用 C 了
- 对象 C 仍然是白色,最终会被错误回收
- 但实际上 A 还在引用 C,C 不应该被回收!

问题二:悬空指针
另一个问题是可能产生悬空指针:
- 垃圾回收器正在处理某个对象
- 用户程序此时删除了对该对象的最后一个引用
- 垃圾回收器可能错误地认为该对象仍然是活跃的
这些问题表明,简单地让垃圾回收器和用户程序并发运行是不安全的。我们需要一些机制来确保并发的正确性。
"强"-"弱" 三色不变式尝试解决不用 STW 的问题
为了解决并发标记中的对象丢失问题,研究人员提出了两个重要的不变式(Invariant)来约束对象引用的修改。这两个不变式就像是交通规则,确保在并发环境下不会发生"交通事故"。
强三色不变式(Strong Tri-Color Invariant): 黑色对象不能直接指向白色对象。
如果严格遵守这个规则,就不会出现对象丢失的问题,因为黑色对象(已完成标记的对象)永远不会指向白色对象(未标记的对象)。

弱三色不变式(Weak Tri-Color Invariant): 黑色对象可以指向白色对象,但指向白色对象的黑色对象必须存在一条从灰色对象出发的路径。
弱三色不变式相对宽松一些,允许黑色对象指向白色对象,但要求这个白色对象必须"有救"——即存在一条从灰色对象(还未完成标记的对象)到该白色对象的路径,确保这个白色对象最终会被标记到。

举个例子来理解弱三色不变式:
- 对象 A(黑色)可以指向对象 C(白色)
- 但必须存在一条路径:灰色对象 B → ... → 白色对象 C
- 这样当处理对象 B 时,最终还是会找到对象 C
这两个不变式为我们提供了理论基础,但关键问题是:如何在实际运行中维护这些不变式?
插入屏障或者删除屏障怎么践行三色不变式
为了在运行时维护三色不变式,有人提出了写屏障(Write Barrier)技术。写屏障是一种在修改指针时触发的机制,可以确保引用关系的改变不会违反三色不变式。
注意,下面的两种屏障模式并没有在 Go 的历史版本中单独出现,插入屏障,即 Dijkstra 屏障,和删除屏障,即 Yuasa 屏障,它们都是研究垃圾回收的专家提出的,不是只有 Go 才使用三色标记法。
插入屏障
插入屏障(Insertion Barrier): 在建立新的引用关系时触发,确保强三色不变式。
// 伪代码:插入屏障
func insertionBarrier(slot *unsafe.Pointer, ptr unsafe.Pointer) {
if getColor(current_goroutine_stack) == BLACK && getColor(ptr) == WHITE {
setColor(ptr, GRAY) // 将白色对象变为灰色
}
*slot = ptr // 执行实际的赋值操作
}当一个黑色对象要指向白色对象时,插入屏障会立即将白色对象标记为灰色,确保它不会被错误回收。
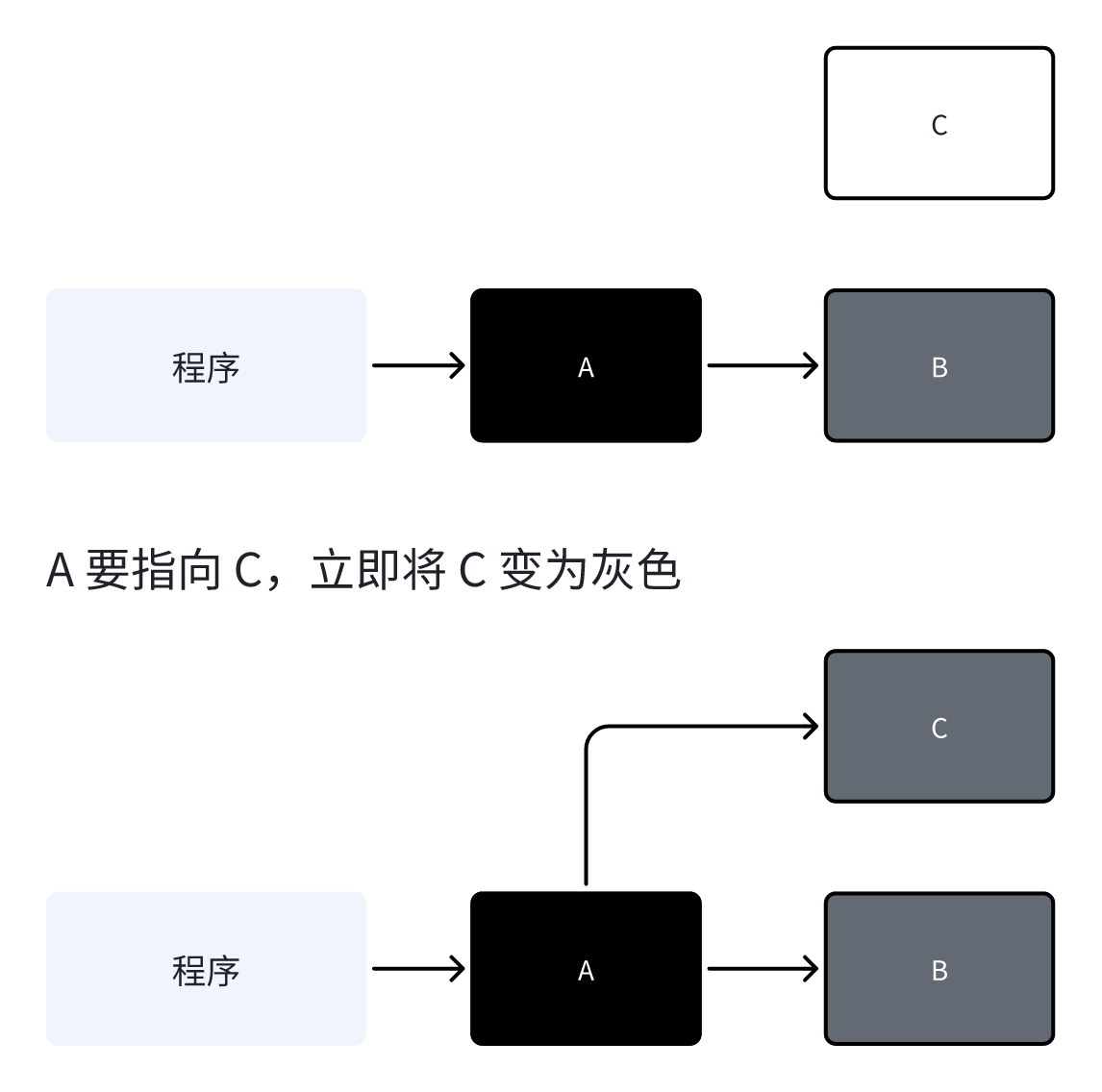
删除屏障
删除屏障(Deletion Barrier): 在删除引用关系时触发,确保弱三色不变式。
// 伪代码:删除屏障
func deletionBarrier(slot *unsafe.Pointer, ptr unsafe.Pointer) {
if getColor(ptr) == WHITE {
setColor(ptr, GRAY) // 将要被删除引用的白色对象标记为灰色
}
*slot = nil // 执行实际的删除操作
}删除屏障在删除对白色对象的引用时,会先将该白色对象标记为灰色,确保即使引用被删除,对象也不会立即变成垃圾。
这么做是为了避免出现下面的情况:
考虑一个典型的问题场景:在并发标记过程中,用户程序可能会删除对某个白色对象的引用,而此时垃圾回收器还没有机会处理这个对象。如果没有删除屏障的保护,就会出现以下危险情况:
场景描述:
- 对象 A(灰色)引用对象 C(白色)
- 对象 B(黑色)现在要引用对象 C
- 用户程序执行:
B.ref = C(建立新引用) - 接着执行:
A.ref = nil(删除原有引用)
没有删除屏障时的问题:
- 当执行
A.ref = nil时,如果没有删除屏障,对象 C 的引用就被直接删除了 - 此时对象 C 可能仍然是白色的(还未被标记过程处理到)
- 虽然对象 B 现在引用着对象 C,但如果对象 B 已经是黑色的,垃圾回收器不会再检查它的新引用
- 结果:对象 C 可能会被错误地回收,即使它仍然被对象 B 引用着
如图: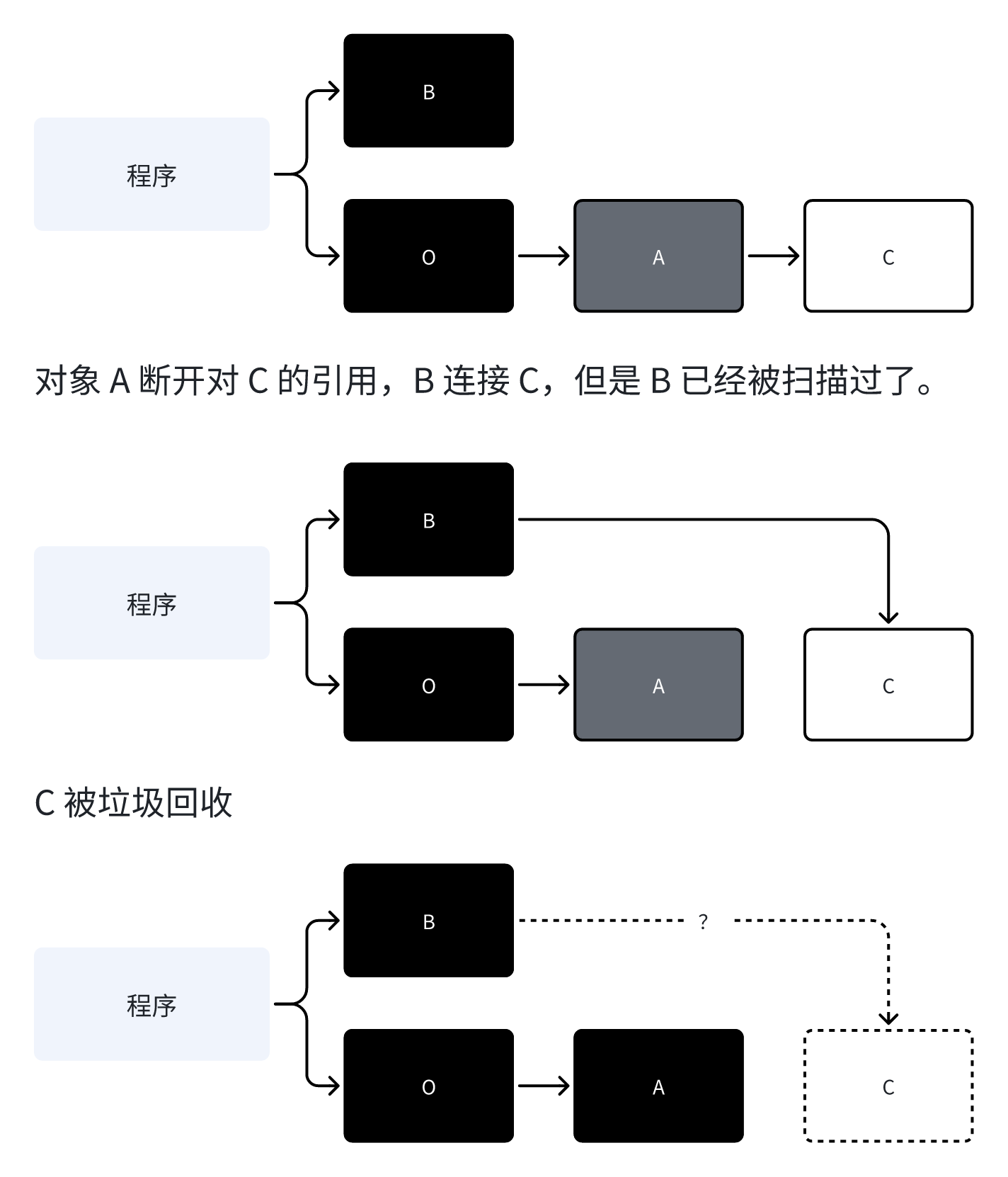
删除屏障的保护作用:
- 当执行
A.ref = nil时,删除屏障会检测到要删除对白色对象 C 的引用 - 它会立即将对象 C 从白色标记为灰色
- 这样即使引用被删除,对象 C 也会在后续的标记过程中被正确处理
- 确保不会出现对象丢失的情况
删除屏障的这种"宁可错杀,不可放过"的保守策略,虽然可能会让一些实际上已经变成垃圾的对象多存活一轮 GC,但它有效地防止了活跃对象被错误回收的严重问题。

有什么问题?
虽然插入屏障和删除屏障都能解决并发标记的正确性问题,但它们各自都有明显的缺陷:
插入屏障的问题:
- 需要在栈上也启用写屏障,但栈上的写操作非常频繁,这会显著影响性能
- 为了避免性能问题,Go 选择不在栈上启用插入屏障,但这意味着在标记结束时仍需要 STW 来重新扫描所有栈
删除屏障的问题:
- 过于保守,会将很多实际上已经是垃圾的对象标记为活跃
- 这导致一些垃圾对象需要等到下一轮 GC 才能被回收,降低了回收效率
- 同样需要在标记结束时 STW 重新对栈进行扫描,以确保所有对象都被正确标记
这两种屏障都无法完全消除 STW,只是缩短了 STW 的时间。不过,Go 团队结合了这两种屏障的优点,提出了一种新的屏障机制:混合写屏障。这种机制在 Go 1.5 中被引入,旨在解决前两种屏障的缺陷,同时保持高效的并发标记能力。接下来我们将深入探讨混合写屏障的工作原理和设计思想。
混合写屏障
Go 1.5 开始引入了混合写屏障(Hybrid Write Barrier),这是垃圾回收器发展史上的一个重要里程碑。混合写屏障巧妙地结合了插入屏障和删除屏障的优点,同时避免了它们的缺点,几乎完全消除了栈重扫描的需要。(在 Go 1.5 之前,是没有屏障机制的,在并发着色和并发标记阶段,都需要使用 STW 扫描)
混合写屏障的设计思想非常巧妙,它的核心原理可以用一句话概括:在 GC 开始时,将所有栈上的对象标记为黑色,然后使用混合屏障来处理堆上的引用变化。
为了理解混合写屏障的精妙之处,我们可以把它想象成一个高明的安全系统。在传统的插入屏障和删除屏障中,我们就像是雇佣了两个不同的保安:一个专门盯着新来的人(插入屏障),一个专门盯着要离开的人(删除屏障)。但这两个保安都有各自的盲点,需要额外的巡逻来确保没有遗漏。
混合写屏障则像是设计了一套更智能的安全系统:在检查开始时,所有已经在场的人(栈上对象)都被认为是可信的,直接给他们发放黑色通行证;然后用一套组合规则来处理后续的人员流动。
混合写屏障的工作原理
混合写屏障的工作可以分为两个关键步骤:
第一步:栈快照(Stack Snapshot)
在 GC 标记阶段开始时,Go 会为每个 goroutine 的栈做一个"快照",将栈上能够到达的所有对象都标记为黑色。这个操作需要短暂的 STW,但时间很短,因为只是简单地遍历栈并标记对象,不需要递归处理。
// 伪代码:栈快照过程
func takeStackSnapshot() {
// 短暂 STW
stopTheWorld()
for goroutine := range allGoroutines {
for stackFrame := range goroutine.stack {
for ref := range stackFrame.getReferences() {
if ref != nil {
setColor(ref, BLACK) // 直接标记为黑色
}
}
}
}
startTheWorld() // 恢复程序执行
}这一步的关键在于,我们不需要递归地标记栈上对象引用的其他对象。我们只是给栈上直接可见的对象一个"免死金牌",确保它们不会被错误回收。
要注意,这里的 “栈对象” 不是说是在栈上分配的对象,栈上的对象是不会被 GC 的,因为栈上的对象在函数调用结束时会自动释放。而这里的 “栈对象” 指的是一个栈上的变量,它引用了堆上的对象。
第二步:混合屏障规则
栈快照完成后,程序继续运行,这时候混合写屏障开始发挥作用。它的规则非常简单但很有效:
// 伪代码:混合写屏障
func hybridWriteBarrier(slot *unsafe.Pointer, ptr unsafe.Pointer) {
// 规则 1:如果要删除的对象是白色,将其标记为灰色(删除屏障的思想)
if *slot != nil && getColor(*slot) == WHITE {
setColor(*slot, GRAY)
}
// 规则 2:如果要插入的对象是白色,将其标记为灰色(插入屏障的思想)
if ptr != nil && getColor(ptr) == WHITE {
setColor(ptr, GRAY)
}
// 执行实际的指针赋值
*slot = ptr
}这个混合规则确保了:
- 任何从堆上对象被删除引用的白色对象都会被标记为灰色(继承删除屏障的保护)
- 任何被堆上对象新引用的白色对象都会被标记为灰色(继承插入屏障的保护)
- 栈上的对象已经在快照时被标记为黑色,不需要屏障保护
为什么混合写屏障这么巧妙?
混合写屏障的巧妙之处在于它解决了前面两种屏障的核心问题:
解决栈扫描问题: 传统的插入屏障和删除屏障都无法在栈上高效工作,因为栈上的指针修改太频繁。混合写屏障通过在 GC 开始时给栈上对象"免死金牌"的方式,彻底避开了这个问题。
想象一下,这就像是在一个大型活动开始前,所有已经到场的 VIP 都拿到了特殊通行证,后续就不需要再对他们进行复杂的安检流程了。
几乎消除 STW: 混合写屏障只需要在开始时进行很短的 STW 来做栈快照,后续的标记过程完全可以与用户程序并发执行,不需要额外的栈重扫描。
一个具体的例子
让我们通过一个具体的例子来看看混合写屏障是如何工作的:
func example() {
// GC 开始前的状态
var a *Object = &Object{name: "A"} // 在栈上
var b *Object = &Object{name: "B"} // 在栈上
a.ref = &Object{name: "C"} // C 在堆上
b.ref = &Object{name: "D"} // D 在堆上
// GC 开始:栈快照阶段
// 此时 a、b 被标记为黑色(栈上对象)
// C、D 仍然是白色(等待标记)
// 用户程序继续运行,修改引用关系
a.ref = b.ref // a 现在指向 D,触发混合写屏障
}在这个例子中,当执行 a.ref = b.ref 时:
- 删除屏障逻辑:
a.ref原来指向对象 C(白色),屏障会将 C 标记为灰色 - 插入屏障逻辑:
b.ref指向对象 D(白色),屏障会将 D 标记为灰色 - 执行实际的赋值操作
这样,无论对象 C 和 D 后续如何被引用或解除引用,它们都不会被错误回收,因为它们已经被标记为灰色,会在后续的标记过程中被正确处理。
混合写屏障的性能优势
相比于前面的方案,混合写屏障带来了显著的性能提升:
STW 时间极短:只需要在开始时做栈快照,通常只需要几微秒到几毫秒,相比之前的几十毫秒甚至更长时间有了质的提升。
并发程度高:标记过程几乎完全与用户程序并发,不会阻塞程序的正常执行。
这就是为什么 Go 1.8 之后的垃圾回收器能够实现如此低的延迟。混合写屏障的引入让 Go 的垃圾回收器真正达到了"软实时"的水平,为 Go 在高性能服务器开发领域的成功奠定了重要基础。
但是,在这里,混合写屏障通过保守地在赋值时将白色对象标灰,虽然避免了错误回收的风险,但也可能标记一些实际上已经不再使用的对象,从而导致它们要等到下一轮 GC 才被清理,这是一种为了确保安全性所做的“延迟回收”权衡。
Go 垃圾回收的完整流程
了解了三色标记法和混合写屏障的原理后,让我们来看看现代 Go 垃圾回收器的完整工作流程。整个过程就像是一场精心编排的舞蹈,每个步骤都有其特定的目的和时机。
GC 的触发时机
Go 的垃圾回收器不是定时触发的,而是基于堆内存的使用情况动态决定的。主要有以下几种触发方式:
自动触发(最常见):
当堆内存的使用量达到上次 GC 后的 GOGC% 时自动触发。默认 GOGC=100,意味着堆大小翻倍时触发 GC。
// 例如:上次 GC 后堆大小为 100MB
// 当堆大小增长到 200MB 时,自动触发下一次 GC手动触发:
程序可以通过调用 runtime.GC() 主动触发垃圾回收。
内存压力触发: 当系统内存不足时,Go 运行时会更激进地触发 GC。
完整的 GC 流程
现代 Go 的垃圾回收过程可以分为以下几个阶段:
阶段 1:标记准备(Mark Setup)
这个阶段需要短暂的 STW,主要做三件事:
// 伪代码:标记准备阶段
func markSetup() {
stopTheWorld() // 开始 STW
// 1. 启用混合写屏障
enableWriteBarrier()
// 2. 为所有 goroutine 做栈快照
for goroutine := range allGoroutines {
scanGoroutineStack(goroutine) // 将栈上对象标记为黑色
}
// 3. 将根对象标记为灰色
scanGlobalVariables()
startTheWorld() // 结束 STW,用户程序继续运行
}这个阶段的 STW 时间通常只有几十到几百微秒,因为只需要扫描栈和全局变量,不需要递归处理对象引用。
阶段 2:并发标记(Concurrent Mark)
标记准备完成后,程序恢复运行,垃圾回收器开始并发标记阶段。这个阶段完全与用户程序并发执行:
// 伪代码:并发标记阶段
func concurrentMark() {
// 处理所有灰色对象
for {
obj := getGrayObject()
if obj == nil {
break // 没有更多灰色对象
}
// 将对象标记为黑色
setColor(obj, BLACK)
// 扫描对象的所有引用
for ref := range obj.getReferences() {
if getColor(ref) == WHITE {
setColor(ref, GRAY) // 将白色对象标记为灰色
}
}
}
}在这个阶段,用户程序可能会不断地修改对象引用关系,混合写屏障会确保这些修改不会导致活跃对象被错误回收。
阶段 3:标记终止(Mark Termination)
当所有灰色对象都被处理完毕后,需要再次短暂的 STW 来完成标记:
// 伪代码:标记终止阶段
func markTermination() {
stopTheWorld() // 开始 STW
// 处理在并发标记阶段产生的剩余灰色对象
drainWorkQueue()
// 关闭写屏障
disableWriteBarrier()
// 准备清除阶段
prepareSweep()
startTheWorld() // 结束 STW
}这个阶段的 STW 时间也很短,通常在几十微秒左右。
阶段 4:并发清除(Concurrent Sweep)
清除阶段也是并发执行的,它会在后台逐渐回收所有白色对象:
// 伪代码:并发清除阶段
func concurrentSweep() {
go func() { // 在后台 goroutine 中执行
for span := range allMemorySpans {
sweepSpan(span) // 清理内存块
}
}()
}
func sweepSpan(span *MemorySpan) {
for obj := range span.objects {
if getColor(obj) == WHITE {
freeObject(obj) // 回收白色对象
} else {
setColor(obj, WHITE) // 重置颜色为白色,准备下次 GC
}
}
}清除阶段会逐步释放内存,并将存活对象的颜色重置为白色,为下一轮 GC 做准备。
实际应用中的垃圾回收调优
理解了 Go 垃圾回收的工作原理后,我们来看看在实际开发中如何调优垃圾回收器的性能。虽然 Go 的垃圾回收器已经非常智能,但在某些特定场景下,适当的调优仍然能够带来显著的性能提升。
监控 GC 性能
在进行任何优化之前,我们首先需要了解当前程序的 GC 表现。Go 提供了多种工具来监控垃圾回收:
使用 GODEBUG 环境变量:
GODEBUG=gctrace=1 go run main.go这会输出详细的 GC 日志,类似于:
gc 1 @0.012s 0%: 0.018+0.46+0.071 ms clock, 0.14+0.042/0.23/0.51+0.57 ms cpu, 4->4->2 MB, 5 MB goal, 8 P让我们解读这个日志:
gc 1:第 1 次垃圾回收@0.012s:程序启动后 0.012 秒触发0%:GC 占用的 CPU 时间百分比0.018+0.46+0.071 ms clock:STW 时间(标记准备 + 标记 + 标记终止)4->4->2 MB:GC 前堆大小 -> GC 后堆大小 -> 存活对象大小5 MB goal:下次 GC 的触发阈值
使用 runtime/debug 包:
package main
import (
"fmt"
"runtime/debug"
"time"
)
func monitorGC() {
var stats debug.GCStats
debug.ReadGCStats(&stats)
fmt.Printf("GC 次数: %d\n", stats.NumGC)
fmt.Printf("总 GC 时间: %v\n", stats.PauseTotal)
if len(stats.Pause) > 0 {
fmt.Printf("最近一次 GC 暂停时间: %v\n", stats.Pause[0])
}
}
func main() {
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
monitorGC()
}
}
}调整 GOGC 参数
GOGC 是最重要的 GC 调优参数,它控制着 GC 的触发频率:
# 设置 GOGC=200,表示堆大小增长 200% 时触发 GC
export GOGC=200
# 设置 GOGC=50,表示堆大小增长 50% 时触发 GC
export GOGC=50
# 禁用自动 GC(只能手动触发)
export GOGC=offGOGC 值的选择策略:
- 高频 GC(GOGC < 100):适用于内存敏感的环境,GC 更频繁但每次回收的内存更少,延迟更低但吞吐量可能下降
- 低频 GC(GOGC > 100):适用于内存充足的环境,GC 不那么频繁但每次处理的对象更多,吞吐量更高但可能有更长的延迟峰值
让我们看一个实际的例子:
package main
import (
"fmt"
"runtime"
"time"
)
func allocateMemory() {
// 模拟内存分配
data := make([][]byte, 1000)
for i := range data {
data[i] = make([]byte, 1024*1024) // 1MB each
}
// 让数据保持一段时间
time.Sleep(100 * time.Millisecond)
}
func main() {
var m1, m2 runtime.MemStats
runtime.ReadMemStats(&m1)
fmt.Printf("开始前 - 堆大小: %d KB, GC 次数: %d\n",
m1.HeapAlloc/1024, m1.NumGC)
// 分配大量内存
for i := 0; i < 10; i++ {
allocateMemory()
}
runtime.ReadMemStats(&m2)
fmt.Printf("结束后 - 堆大小: %d KB, GC 次数: %d\n",
m2.HeapAlloc/1024, m2.NumGC)
fmt.Printf("触发了 %d 次 GC\n", m2.NumGC-m1.NumGC)
}减少 GC 压力的编程技巧
除了调整参数,我们还可以通过改进代码来减少 GC 压力:
对象池技术:
对于频繁创建和销毁的对象,可以使用对象池来避免重复分配:
package main
import (
"sync"
)
// 使用 sync.Pool 实现对象池
var bufferPool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024) // 创建 1KB 缓冲区
},
}
func processData(data []byte) {
// 从池中获取缓冲区
buffer := bufferPool.Get().([]byte)
defer bufferPool.Put(buffer) // 用完后放回池中
// 使用缓冲区处理数据
copy(buffer, data)
// ... 处理逻辑
}避免不必要的指针:
减少指针的使用可以降低 GC 扫描的负担:
// 不好的做法:大量指针
type BadNode struct {
Value *int
Next *BadNode
}
// 更好的做法:减少指针使用
type GoodNode struct {
Value int // 直接存储值而不是指针
Next *GoodNode
}
// 对于大量数据,考虑使用数组而不是链表
type DataArray struct {
Values []int // 连续内存,GC 扫描更高效
}批量处理:
将多个小操作合并为一个大操作,减少内存分配次数:
// 不好的做法:频繁字符串拼接
func badStringConcat(parts []string) string {
result := ""
for _, part := range parts {
result += part // 每次都会创建新字符串
}
return result
}
// 更好的做法:使用 strings.Builder
func goodStringConcat(parts []string) string {
var builder strings.Builder
builder.Grow(len(parts) * 10) // 预分配容量
for _, part := range parts {
builder.WriteString(part)
}
return builder.String()
}特殊场景的调优策略
不同的应用场景需要不同的调优策略:
Web 服务器:
- 优先考虑响应延迟,可以设置较小的 GOGC 值(如 50-80)
- 使用连接池、对象池等技术减少临时对象分配
- 监控每个请求的内存分配情况
批处理任务:
- 优先考虑吞吐量,可以设置较大的 GOGC 值(如 200-400)
- 处理完一批数据后手动调用
runtime.GC()进行清理 - 考虑分批处理大数据集,避免一次性加载过多数据
实时系统:
- 对延迟极其敏感,可能需要禁用自动 GC(GOGC=off)
- 手动控制 GC 触发时机,在业务低峰期进行清理
- 使用内存预分配策略,避免运行时的内存分配
通过合理的监控、参数调整和代码优化,我们可以让 Go 的垃圾回收器更好地为我们的应用服务,在保证程序正确性的同时获得最佳的性能表现。
总结
从最初的标记-清除算法到现在的混合写屏障,Go 语言的垃圾回收器经历了一个不断进化和优化的过程。这个过程就像是从马车时代进入到了自动驾驶汽车时代——不仅解放了程序员的双手,还提供了更安全、更高效的内存管理体验。
在今天的云原生时代,Go 语言凭借其出色的垃圾回收能力,成为了构建高性能服务器应用的首选语言之一。从 Docker 到 Kubernetes,从 Prometheus 到 Istio,这些改变世界的项目都选择了 Go,很大程度上正是因为它能够在保证开发效率的同时提供出色的运行时性能。
当然,Go 的垃圾回收器仍在不断进化。Go 团队持续在降低延迟、提高吞吐量、减少内存占用等方面进行优化。未来我们可能会看到更多令人兴奋的改进,比如更智能的 GC 调度、更精确的内存管理等等。
作为 Go 程序员,我们不需要成为垃圾回收专家,但理解其基本原理和调优方法,能够帮助我们写出更高效的代码,在需要的时候进行有针对性的优化。这就像开车一样——你不需要成为汽车工程师,但了解发动机的基本工作原理,能够让你更好地驾驭你的座驾。
希望通过今天的探讨,你对 Go 语言的垃圾回收机制有了更深入的理解。下次当你的 Go 程序在后台静静地进行垃圾回收时,你就知道那里正在发生着多么精妙的魔法。