
当我们谈论 Go 语言的并发编程时,总是绕不开一个话题:为什么 Go 能够轻松地启动成千上万个 goroutine,而其他语言的线程却如此昂贵?答案就隐藏在 Go 的协程调度策略背后——GMP 模型。
本文将带你深入理解 Go 语言的协程调度机制,从操作系统线程的局限性说起,逐步揭开 GMP 模型的神秘面纱,最后通过具体的调度场景让你真正掌握 Go 并发编程的精髓。
操作系统线程的现实困境
在深入 Go 的协程世界之前,我们先来理解传统线程模型的局限性。
想象一下你是一家餐厅的老板,每当有客人来用餐时,你就雇佣一名专门的服务员来服务这位客人。这看起来很合理,每个客人都能得到专属服务。但问题来了:如果同时来了一万个客人,你就需要雇佣一万名服务员。每个服务员不仅需要工资(内存),还需要独立的工作空间(栈空间),更要命的是,当服务员们需要协调工作时(上下文切换),整个餐厅的效率就会急剧下降。
这就是操作系统线程面临的现实困境。在传统的线程模型中:
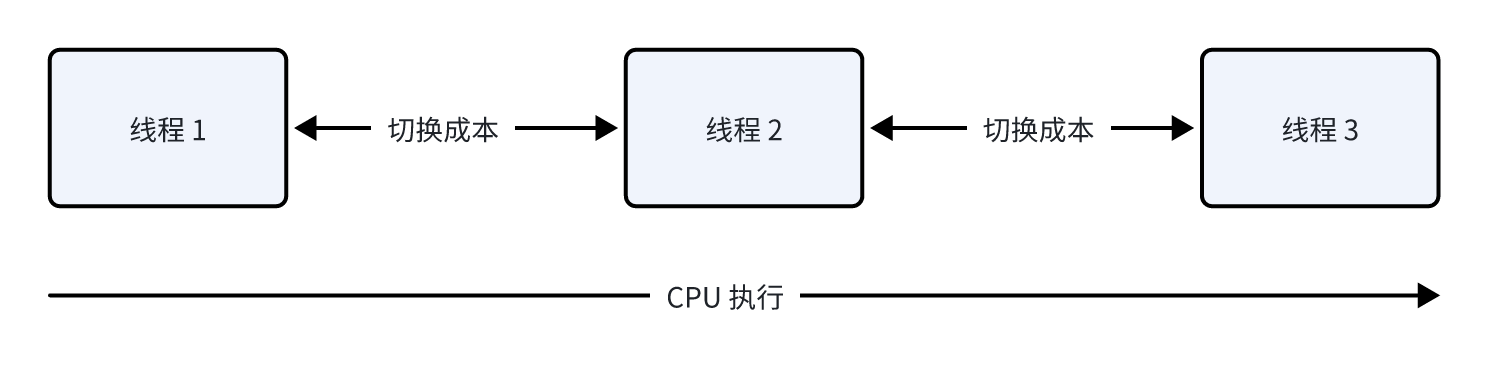
线程是操作系统调度的最小单位,每个线程都需要独立的栈空间,通常在 1-8MB 之间。当你创建大量线程时,仅仅是内存开销就足以让系统崩溃。更严重的是,线程间的上下文切换成本极高,因为需要保存和恢复大量的 CPU 寄存器状态,这个过程可能需要几千个 CPU 周期。
在高并发场景下,操作系统可能会花费大量时间在线程调度上,而真正用于处理业务逻辑的时间反而很少。这就是为什么传统的多线程编程在面对大并发时显得力不从心的根本原因。
协程的革命性思维
协程(Coroutine)的出现彻底改变了这种局面。如果说线程是“重量级”的解决方案,那么协程就是“轻量级”的革命。
回到餐厅的比喻:协程的思维是这样的——我们不需要为每个客人雇佣专门的服务员,而是训练几个非常灵活的服务员,他们可以同时服务多个客人。当一个客人在看菜单思考时,服务员不会傻等着,而是立即去服务其他客人。这样,少数几个服务员就能高效地服务大量客人。
协程的本质是用户态的轻量级线程,它们运行在用户空间,不需要操作系统内核的参与。协程的切换完全由程序控制,切换成本极低,通常只需要几个 CPU 周期。更重要的是,协程的栈空间可以动态增长,初始时可能只有几 KB,需要时才会扩展。
这种设计带来的好处是显而易见的:我们可以轻松创建成千上万个协程而不用担心资源消耗,每个协程都可以专注于处理一个独立的任务,而协程间的切换几乎没有性能损耗。
Go 的 Goroutine:协程的 Go 式实现
Go 语言将协程的概念进一步发扬光大,创造了 goroutine 这个独特的并发原语。
Goroutine 不仅仅是简单的协程实现,它更像是 Go 团队对并发编程的深度思考的结晶。一个 goroutine 的初始栈大小只有 2KB,相比传统线程的 MB 级别栈空间,这简直是质的飞跃。当栈空间不够时,Go 运行时会自动进行栈扩容,这个过程对程序员来说是完全透明的。
更重要的是,goroutine 的设计哲学体现了 Go 语言"Don't communicate by sharing memory; share memory by communicating"的核心理念。通过 channel 这个强大的通信机制,goroutine 之间可以安全、优雅地进行数据交换,避免了传统多线程编程中复杂的锁机制。
创建一个 goroutine 非常简单:
go func() {
fmt.Println("Hello from goroutine!")
}()这行代码启动了一个新的 goroutine,它几乎不消耗任何资源,启动速度极快。你可以在一个程序中轻松启动数万个这样的 goroutine,而系统依然能够流畅运行。
但这里有一个关键问题:如果我们能够创建数万个 goroutine,但操作系统只给我们几个或几十个线程,那么这些 goroutine 是如何在有限的线程上运行的呢?这就引出了 Go 运行时调度器的核心挑战,也是 GMP 模型要解决的根本问题。
被废弃的 G-M 模型:历史的教训
为了更好地使用并发资源,我们会采用 M:N 的模式,即 M 个操作系统线程(Machine)去执行 N 个 goroutine(Goroutine)。这个模式的核心在于调度器,它负责将 goroutine 分配给操作系统线程。
这种模式下就需要一个高效的调度策略来管理 goroutine 和操作系统线程之间的映射关系。现在的 Go 运行时使用的是 GMP 模型,但在理解现在的 GMP 模型之前,我们需要了解 Go 古早时期的 G-M 模型,以及它为什么被废弃。这段历史不仅有助于我们理解设计演进的思路,更能让我们深刻体会到好的调度器设计是多么不容易。
早期的 G-M 模型相对简单:G 代表 Goroutine,M 代表 Machine(操作系统线程)。所有的 Goroutine 被放在一个全局队列中,所有的 M 都从这个全局队列中获取 Goroutine 来执行。
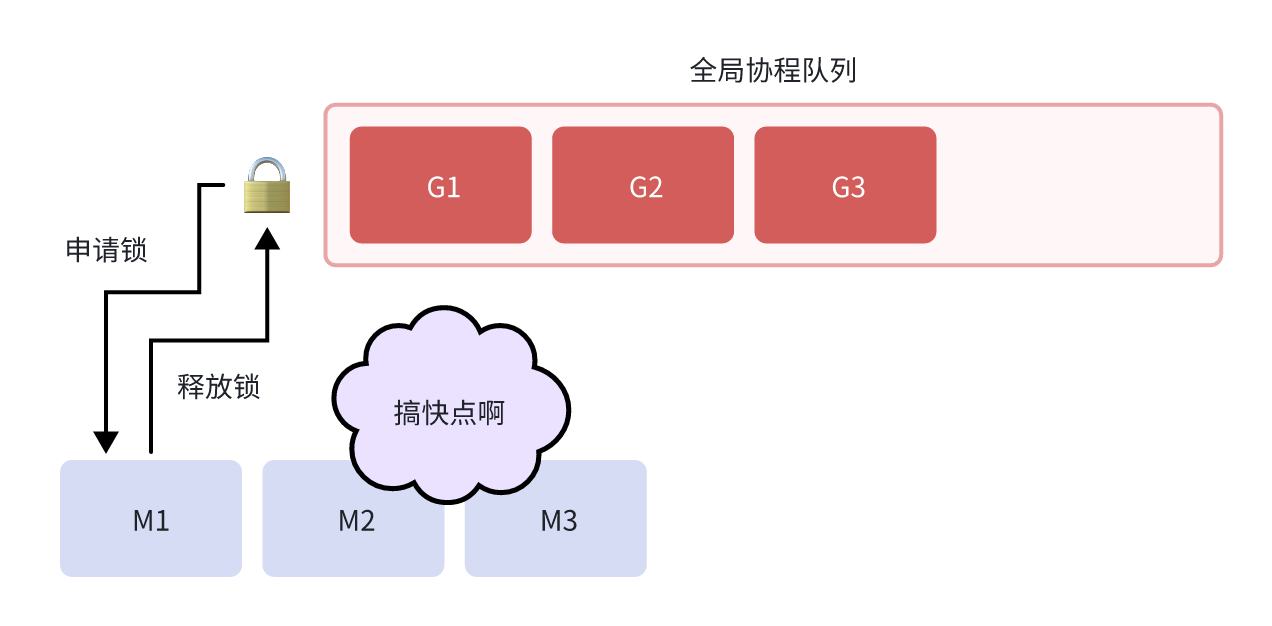
这个设计看起来很直观,就像一个工厂的生产线:所有的任务(Goroutine)都放在一个传送带(全局队列)上,所有的工人(M)都从传送带上取任务来完成。
但是,这个简单的设计存在致命的性能问题:
全局锁竞争:所有的 M 都需要从同一个全局队列中获取 Goroutine,这意味着每次获取都需要加锁。在高并发场景下,大量的 M 会激烈竞争这个全局锁,导致严重的性能瓶颈。
缺乏局部性:当一个 Goroutine 创建了新的 Goroutine 时,新的 Goroutine 会被放到全局队列的末尾,而不是在创建它的 M 上运行。这破坏了缓存局部性,影响了性能。
M 阻塞问题:当一个 M 因为系统调用而阻塞时,它上面运行的 Goroutine 也会被阻塞,即使这个 Goroutine 本身并不需要等待系统调用的结果。
用餐厅的比喻来说,这就像所有的服务员都必须排队到一个统一的取餐窗口拿菜,不仅效率低下,而且当一个服务员因为特殊原因被耽搁时,他手上的所有订单都会被延误。
正是因为这些问题,Go 团队在 1.1 版本中引入了革命性的 GMP 模型,这个改进被认为是 Go 并发性能的一个里程碑。
新的 GMP 模型:调度策略的艺术
GMP 模型的引入彻底解决了 G-M 模型的痛点,它引入了一个关键的中间层:P(Processor)。
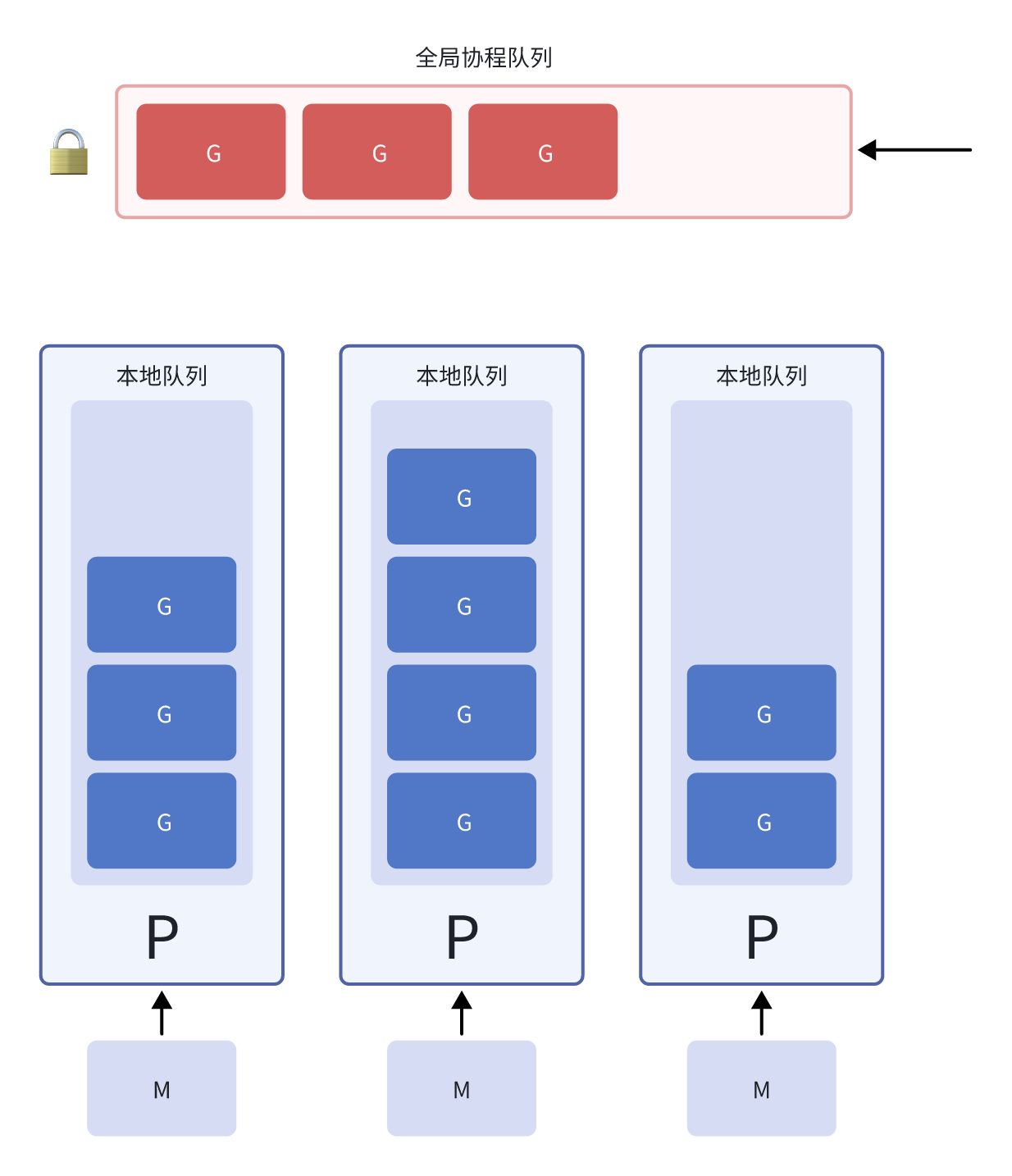
让我们重新定义这三个核心组件:
G(Goroutine):代表一个 goroutine,包含了 goroutine 的栈、程序计数器、以及其他执行上下文信息。每个 G 都有自己的栈空间,初始大小为 2KB,可以动态扩展。
M(Machine):代表一个操作系统线程,是真正执行代码的实体。M 必须绑定一个 P 才能执行 Goroutine。M 的数量通常等于 CPU 核心数,但在某些情况下可能会创建更多。
P(Processor):这是 GMP 模型的创新所在。P 代表一个逻辑处理器,它维护着一个本地的 Goroutine 队列。P 的数量通常等于 GOMAXPROCS 的值,默认为 CPU 核心数。
这个设计的巧妙之处在于:每个 P 都有自己的本地队列,M 只需要从绑定的 P 的本地队列中获取 Goroutine,大大减少了锁竞争。同时,当本地队列为空时,P 可以从其他 P 的队列中"偷取"Goroutine,这种工作窃取(work-stealing)机制保证了负载均衡。
用一个更贴切的比喻来说:GMP 模型就像一个现代化的餐厅管理系统。每个区域(P)都有自己的服务员(M)和订单队列,服务员主要处理自己区域的订单。但当某个区域比较空闲时,服务员可以去帮助其他繁忙区域处理订单。同时,还有一个总的订单池(全局队列)来处理溢出的订单。
这种设计带来了显著的性能提升:
- 减少锁竞争:大部分情况下,M 只需要访问绑定 P 的本地队列,无需全局锁。
- 提高缓存局部性:相关的 Goroutine 更可能在同一个 P 上运行,提高了缓存命中率。
- 负载均衡:通过工作窃取机制,确保所有的 P 都能充分利用。
- 系统调用优化:当 M 因系统调用阻塞时,P 可以绑定到其他 M 继续工作。
新启动一个 Go 程序时,发生了什么?
当你运行一个 Go 程序时,一个精妙的调度器初始化过程在幕后悄然进行。
首先,Go 运行时会创建一个主 Goroutine 来执行 main 函数。这个 Goroutine 被称为 G0,它是整个程序的起点。同时,运行时会根据 GOMAXPROCS 的设置创建相应数量的 P。默认情况下,GOMAXPROCS 等于机器的 CPU 核心数,这意味着你有几个 CPU 核心,就会创建几个 P。
接下来,运行时会创建第一个 M(M0),并将其与第一个 P(P0)绑定。这个 M0 开始执行主 Goroutine。其他的 P 初始时处于空闲状态,等待有 Goroutine 需要执行时再创建对应的 M。
这个过程就像是在开餐厅的第一天:你先安排了几个服务区域(P),雇佣了第一个服务员(M0)来负责第一个区域(P0),并开始接待第一位客人(主 Goroutine)。其他区域暂时空置,等有更多客人时再安排服务员。
当程序中创建新的 Goroutine 时,这些 Goroutine 会优先放入当前 P 的本地队列。如果有空闲的 P,运行时可能会创建新的 M 来执行这些 Goroutine,从而充分利用多核优势。
本地队列满了怎么办?
每个 P 的本地队列都有容量限制,通常为 256 个 Goroutine。当本地队列满了怎么办?这是一个关键的调度决策点。
当 P 的本地队列已满时,Go 调度器会采用一种巧妙的策略:它会将本地队列中的一半 Goroutine 移动到全局队列中,然后将新创建的 Goroutine 放入本地队列。
这种策略的设计考虑了多个因素:
首先,它避免了频繁地向全局队列添加单个 Goroutine,减少了全局锁的争用。通过批量移动,提高了操作效率。
其次,它保持了本地队列的活跃性。移动一半而不是全部,意味着本地队列仍然保留了一些 Goroutine,可以继续提供良好的缓存局部性。
最后,它为全局队列提供了稳定的 Goroutine 供应,确保其他空闲的 P 能够找到工作。
这个过程就像餐厅的订单管理:当某个区域的订单堆积过多时,经理会将一半订单转移到总订单池,既缓解了区域压力,又为其他空闲区域提供了工作机会。
本地队列空了怎么办?
当一个 P 的本地队列为空时,对应的 M 并不会闲着,而是会主动寻找工作。这个寻找过程遵循一个精心设计的优先级策略。
首先,M 会检查全局队列是否有 Goroutine。如果有,它会从全局队列中取出一部分 Goroutine 到自己的本地队列中。为了公平性,每次从全局队列取出的 Goroutine 数量是有限制的,通常是 min(len(global_queue)/GOMAXPROCS, 127)。
如果全局队列也为空,M 就会开始"工作窃取"。它会随机选择其他的 P,尝试从它们的本地队列中窃取一半的 Goroutine。这个窃取过程是随机的,避免了多个空闲 M 同时瞄准同一个 P 的情况。
如果工作窃取也没有成功,M 会检查网络轮询器(netpoller)中是否有就绪的 Goroutine。网络轮询器主要处理网络 I/O 相关的 Goroutine,当网络事件就绪时,相关的 Goroutine 就可以继续执行。
如果以上步骤都没有找到可执行的 Goroutine,M 就会进入自旋状态,不断重复上述查找过程。如果自旋一段时间后仍然没有找到工作,M 就会休眠,直到有新的 Goroutine 需要执行时被唤醒。
这个机制确保了系统资源的充分利用:只要有 Goroutine 需要执行,就会有 M 来执行它们。同时,通过自旋和休眠机制,避免了无意义的 CPU 消耗。
协程阻塞线程怎么办?
这是 GMP 模型设计中最巧妙的部分之一。当一个 Goroutine 需要进行系统调用(如文件 I/O、网络操作等)时,执行它的 M 会被操作系统阻塞。但这不意味着 P 上的其他 Goroutine 也要等待。
Go 调度器采用了 “hand off” 机制:当 M 即将进入系统调用时,它会将自己绑定的 P 交给其他空闲的 M,或者创建一个新的 M 来接管这个 P。这样,P 上的其他 Goroutine 就能继续执行,不会因为一个 Goroutine 的阻塞而影响整体性能。
当系统调用完成后,原来的 M 会尝试重新获取一个 P。如果能够获取到,它就继续执行;如果所有的 P 都被占用,这个 M 和它上面的 Goroutine 就会进入休眠状态,等待 P 可用时再被唤醒。
这种机制的好处是显而易见的:系统调用的阻塞不会影响其他 Goroutine 的执行,保证了程序的整体响应性。同时,通过动态创建和销毁 M,系统能够根据实际需要调整资源使用。
用餐厅比喻来说:当一个服务员需要去厨房等待特殊菜品时,他会把自己负责的区域交给其他服务员或者新招的临时工,确保客人不会因为一个服务员的暂时离开而得不到服务。
有闲着的 M 和 P 时,叫醒它们
Go 调度器还有一个重要的机制:当有新的 Goroutine 需要执行时,如何高效地唤醒休眠的 M 和利用空闲的 P?
当新的 Goroutine 被创建时,如果当前 P 的本地队列有空间,新 Goroutine 会直接加入本地队列。但如果检测到有空闲的 P,调度器会尝试创建新的 M 或唤醒休眠的 M 来执行这些 Goroutine。
这个唤醒机制是智能的:它不会盲目地为每个新 Goroutine 创建 M,而是根据系统负载和可用资源来决定。如果系统已经很繁忙,新 Goroutine 可能会等待;如果系统有闲置资源,就会立即分配 M 来执行。
此外,当从网络轮询器中获取到就绪的网络 Goroutine 时,如果没有空闲的 P 来处理,调度器也会尝试唤醒休眠的 M 或创建新的 M。
这种机制确保了系统资源的动态平衡:在负载高时充分利用资源,在负载低时避免浪费资源。
全局队列里面的 Goroutine 会被一直冷落吗?
在 GMP 模型中,大部分时候 M 都优先处理自己 P 的本地队列,那么全局队列中的 Goroutine 会不会被遗忘?
例如,有两个 P,它们之中运行的 G 都在不断地产生新的 Goroutine,这就导致本地队列不会为空,如果不加以处理的话,全局队列中的 Goroutine 可能会被长时间忽略。
Go 调度器通过一个巧妙的机制来防止全局队列中的 Goroutine 被“饿死”:调度轮次检查。
每个 P 都有一个调度计数器,每当它执行一定数量的 Goroutine 后(通常是 61 次),就会强制检查全局队列。如果全局队列中有 Goroutine,P 会从中取出一个来执行,确保全局队列中的 Goroutine 不会被无限期地忽略。
这个数字 61 的选择也是有考虑的:它足够大,避免频繁地检查全局队列影响性能;同时又足够小,确保全局队列中的 Goroutine 不会等待太久。
此外,当 P 的本地队列为空时,它也会优先检查全局队列,这为全局队列提供了额外的执行机会。
这种设计体现了调度器在性能和公平性之间的平衡:既要保证高性能的本地执行,又要确保所有 Goroutine 都能得到执行机会。
整体再来看一下
现在让我们把所有的片段组合起来,看看 GMP 模型是如何协调工作的。
想象一个繁忙的软件公司,有多个开发团队(P),每个团队都有自己的任务列表(本地队列)和开发人员(M)。还有一个公共的任务池(全局队列),用来存放溢出的或者新分配的任务。
在正常情况下,每个开发人员专注于处理自己团队的任务,这保证了高效率和良好的协作。当某个团队的任务完成后,开发人员不会闲着,而是主动去帮助其他忙碌的团队,这就是工作窃取机制。
当有开发人员需要等待外部资源(如等待服务器响应)时,他们会暂时离开,让其他人接管自己的工作,这就是系统调用的处理方式。
定期地,每个团队都会检查公共任务池,确保没有任务被遗忘,这保证了全局队列的公平性。
这整个系统是自适应的:当工作量大时,会有更多的开发人员参与;当工作量小时,部分开发人员会休息以节省资源。
这就是 GMP 模型的精髓:通过精心设计的调度策略,在性能、公平性和资源利用率之间找到了最佳平衡点。
其他语言怎么做的?
理解 Go 的 GMP 模型后,我们不妨看看其他语言是如何处理并发的,这能让我们更好地理解 Go 设计的独特性。
C/C++ 的线程模型通常依赖于操作系统的线程库(如 pthreads),每个线程都有独立的栈空间和调度策略。虽然可以使用线程池来复用线程,但创建和销毁线程的开销仍然很大。
Java 主要依赖操作系统线程,每个 Thread 对象对应一个 OS 线程。虽然 Java 有线程池来复用线程,但创建大量线程仍然会遇到资源限制。最新的 Project Loom 引入了虚拟线程(Virtual Threads),这是 Java 对协程概念的实现,但它的调度策略相对简单,主要是在 I/O 阻塞时切换。
Python 由于 GIL(全局解释器锁)的存在,实际上无法实现真正的并行执行。虽然有 asyncio 库支持协程,但调度机制相对简单,主要基于事件循环。
Rust 采用了不同的方式,它的 async/await 模型提供了零成本抽象的异步编程,但需要选择特定的运行时(如 Tokio)来处理调度。
Erlang/Elixir 有自己的轻量级进程模型,这与 Go 的 Goroutine 类似,但它们的调度器相对简单,主要基于抢占式调度。
相比之下,Go 的 GMP 模型在复杂性和性能之间找到了很好的平衡。它既提供了高性能的并发执行,又保持了相对简单的编程模型。
总结
Go 的 GMP 模型是现代并发编程的一个杰作,它解决了传统线程模型的诸多问题,为 Go 语言的高并发性能奠定了基础。
这个模型的成功在于它的几个关键设计决策:
分层设计:通过引入 P 这个中间层,实现了调度的层次化,既减少了锁竞争,又保持了灵活性。
本地优先,全局兜底:优先使用本地队列提高性能,同时通过全局队列保证公平性。
工作窃取:通过随机化的工作窃取机制,实现了自动的负载均衡。
异步化系统调用:通过 hand off 机制,避免了系统调用对并发性能的影响。
自适应资源管理:根据实际负载动态创建和销毁 M,实现了资源的高效利用。
理解 GMP 模型不仅有助于我们写出更高效的 Go 代码,更能让我们深刻理解并发编程的本质。当你下次在 Go 中轻松地启动成千上万个 Goroutine 时,记住这背后有一个精妙的调度器在默默地协调着一切,这就是工程之美的体现。
正如 Go 语言的座右铭所说:"Don't communicate by sharing memory; share memory by communicating"。GMP 模型正是这一理念在语言运行时层面的完美实现,它让并发编程变得简单而高效,这也是 Go 语言在云计算和微服务时代能够脱颖而出的重要原因之一。